[转]用C#实现网络爬虫
原文 http://www.cnblogs.com/Jiajun/archive/2012/06/16/2552103.html
网络爬虫在信息检索与处理中有很大的作用,是收集网络信息的重要工具。
接下来就介绍一下爬虫的简单实现。
爬虫的工作流程如下
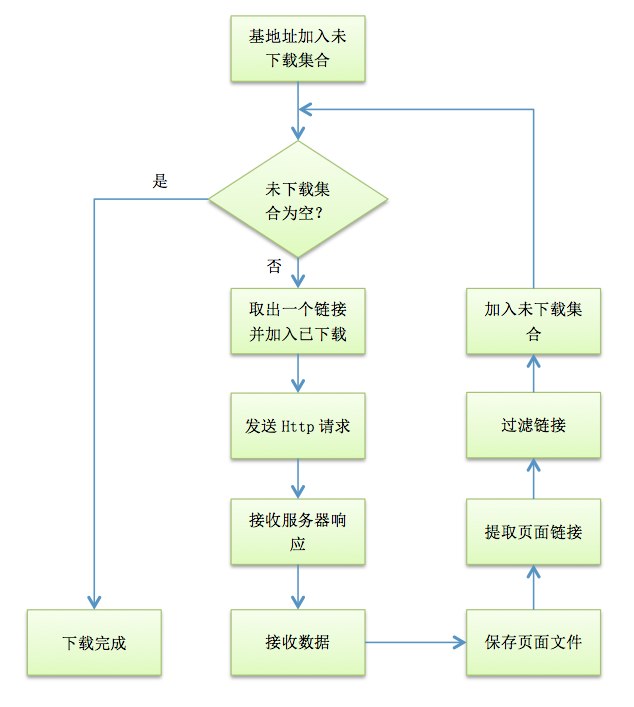
爬虫自指定的URL地址开始下载网络资源,直到该地址和所有子地址的指定资源都下载完毕为止。
下面开始逐步分析爬虫的实现。
1. 待下载集合与已下载集合
为了保存需要下载的URL,同时防止重复下载,我们需要分别用了两个集合来存放将要下载的URL和已经下载的URL。
因为在保存URL的同时需要保存与URL相关的一些其他信息,如深度,所以这里我采用了Dictionary来存放这些URL。
具体类型是Dictionary<string, int> 其中string是Url字符串,int是该Url相对于基URL的深度。
每次开始时都检查未下载的集合,如果已经为空,说明已经下载完毕;如果还有URL,那么就取出第一个URL加入到已下载的集合中,并且下载这个URL的资源。
2. HTTP请求和响应
C#已经有封装好的HTTP请求和响应的类HttpWebRequest和HttpWebResponse,所以实现起来方便不少。
为了提高下载的效率,我们可以用多个请求并发的方式同时下载多个URL的资源,一种简单的做法是采用异步请求的方法。
控制并发的数量可以用如下方法实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | private void DispatchWork() { if (_stop) //判断是否中止下载 { return; } for (int i = 0; i < _reqCount; i++) { if (!_reqsBusy[i]) //判断此编号的工作实例是否空闲 { RequestResource(i); //让此工作实例请求资源 } } } |
由于没有显式开新线程,所以用一个工作实例来表示一个逻辑工作线程
1 2 | private bool[] _reqsBusy = null; //每个元素代表一个工作实例是否正在工作 private int _reqCount = 4; //工作实例的数量 |
每次一个工作实例完成工作,相应的_reqsBusy就设为false,并调用DispatchWork,那么DispatchWork就能给空闲的实例分配新任务了。
接下来是发送请求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | private void RequestResource(int index) { int depth; string url = ""; try { lock (_locker) { if (_urlsUnload.Count <= 0) //判断是否还有未下载的URL { _workingSignals.FinishWorking(index); //设置工作实例的状态为Finished return; } _reqsBusy[index] = true; _workingSignals.StartWorking(index); //设置工作状态为Working depth = _urlsUnload.First().Value; //取出第一个未下载的URL url = _urlsUnload.First().Key; _urlsLoaded.Add(url, depth); //把该URL加入到已下载里 _urlsUnload.Remove(url); //把该URL从未下载中移除 } HttpWebRequest req = (HttpWebRequest)WebRequest.Create(url); req.Method = _method; //请求方法 req.Accept = _accept; //接受的内容 req.UserAgent = _userAgent; //用户代理 RequestState rs = new RequestState(req, url, depth, index); //回调方法的参数 var result = req.BeginGetResponse(new AsyncCallback(ReceivedResource), rs); //异步请求 ThreadPool.RegisterWaitForSingleObject(result.AsyncWaitHandle, //注册超时处理方法 TimeoutCallback, rs, _maxTime, true); } catch (WebException we) { MessageBox.Show("RequestResource " + we.Message + url + we.Status); } } |
第7行为了保证多个任务并发时的同步,加上了互斥锁。_locker是一个Object类型的成员变量。
第9行判断未下载集合是否为空,如果为空就把当前工作实例状态设为Finished;如果非空则设为Working并取出一个URL开始下载。当所有工作实例都为Finished的时候,说明下载已经完成。由于每次下载完一个URL后都调用DispatchWork,所以可能激活其他的Finished工作实例重新开始工作。
第26行的请求的额外信息在异步请求的回调方法作为参数传入,之后还会提到。
第27行开始异步请求,这里需要传入一个回调方法作为响应请求时的处理,同时传入回调方法的参数。
第28行给该异步请求注册一个超时处理方法TimeoutCallback,最大等待时间是_maxTime,且只处理一次超时,并传入请求的额外信息作为回调方法的参数。
RequestState的定义是
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | class RequestState { private const int BUFFER_SIZE = 131072; //接收数据包的空间大小 private byte[] _data = new byte[BUFFER_SIZE]; //接收数据包的buffer private StringBuilder _sb = new StringBuilder(); //存放所有接收到的字符 public HttpWebRequest Req { get; private set; } //请求 public string Url { get; private set; } //请求的URL public int Depth { get; private set; } //此次请求的相对深度 public int Index { get; private set; } //工作实例的编号 public Stream ResStream { get; set; } //接收数据流 public StringBuilder Html { get { return _sb; } } public byte[] Data { get { return _data; } } public int BufferSize { get { return BUFFER_SIZE; } } public RequestState(HttpWebRequest req, string url, int depth, int index) { Req = req; Url = url; Depth = depth; Index = index; } } |
TimeoutCallback的定义是
1 2 3 4 5 6 7 8 9 10 11 12 13 | private void TimeoutCallback(object state, bool timedOut) { if (timedOut) //判断是否是超时 { RequestState rs = state as RequestState; if (rs != null) { rs.Req.Abort(); //撤销请求 } _reqsBusy[rs.Index] = false; //重置工作状态 DispatchWork(); //分配新任务 } } |
接下来就是要处理请求的响应了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | private void ReceivedResource(IAsyncResult ar) { RequestState rs = (RequestState)ar.AsyncState; //得到请求时传入的参数 HttpWebRequest req = rs.Req; string url = rs.Url; try { HttpWebResponse res = (HttpWebResponse)req.EndGetResponse(ar); //获取响应 if (_stop) //判断是否中止下载 { res.Close(); req.Abort(); return; } if (res != null && res.StatusCode == HttpStatusCode.OK) //判断是否成功获取响应 { Stream resStream = res.GetResponseStream(); //得到资源流 rs.ResStream = resStream; var result = resStream.BeginRead(rs.Data, 0, rs.BufferSize, //异步请求读取数据 new AsyncCallback(ReceivedData), rs); } else //响应失败 { res.Close(); rs.Req.Abort(); _reqsBusy[rs.Index] = false; //重置工作状态 DispatchWork(); //分配新任务 } } catch (WebException we) { MessageBox.Show("ReceivedResource " + we.Message + url + we.Status); } } |
第19行这里采用了异步的方法来读数据流是因为我们之前采用了异步的方式请求,不然的话不能够正常的接收数据。
该异步读取的方式是按包来读取的,所以一旦接收到一个包就会调用传入的回调方法ReceivedData,然后在该方法中处理收到的数据。
该方法同时传入了接收数据的空间rs.Data和空间的大小rs.BufferSize。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | private void ReceivedData(IAsyncResult ar) { RequestState rs = (RequestState)ar.AsyncState; //获取参数 HttpWebRequest req = rs.Req; Stream resStream = rs.ResStream; string url = rs.Url; int depth = rs.Depth; string html = null; int index = rs.Index; int read = 0; try { read = resStream.EndRead(ar); //获得数据读取结果 if (_stop)//判断是否中止下载 { rs.ResStream.Close(); req.Abort(); return; } if (read > 0) { MemoryStream ms = new MemoryStream(rs.Data, 0, read); //利用获得的数据创建内存流 StreamReader reader = new StreamReader(ms, _encoding); string str = reader.ReadToEnd(); //读取所有字符 rs.Html.Append(str); // 添加到之前的末尾 var result = resStream.BeginRead(rs.Data, 0, rs.BufferSize, //再次异步请求读取数据 new AsyncCallback(ReceivedData), rs); return; } html = rs.Html.ToString(); SaveContents(html, url); //保存到本地 string[] links = GetLinks(html); //获取页面中的链接 AddUrls(links, depth + 1); //过滤链接并添加到未下载集合中 _reqsBusy[index] = false; //重置工作状态 DispatchWork(); //分配新任务 } catch (WebException we) { MessageBox.Show("ReceivedData Web " + we.Message + url + we.Status); } } |
第14行获得了读取的数据大小read,如果read>0说明数据可能还没有读完,所以在27行继续请求读下一个数据包;
如果read<=0说明所有数据已经接收完毕,这时rs.Html中存放了完整的HTML数据,就可以进行下一步的处理了。 第26行把这一次得到的字符串拼接在之前保存的字符串的后面,最后就能得到完整的HTML字符串。 然后说一下判断所有任务完成的处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | private void StartDownload() { _checkTimer = new Timer(new TimerCallback(CheckFinish), null, 0, 300); DispatchWork(); } private void CheckFinish(object param) { if (_workingSignals.IsFinished()) //检查是否所有工作实例都为Finished { _checkTimer.Dispose(); //停止定时器 _checkTimer = null; if (DownloadFinish != null && _ui != null) //判断是否注册了完成事件 { _ui.Dispatcher.Invoke(DownloadFinish, _index); //调用事件 } } } |
第3行创建了一个定时器,每过300ms调用一次CheckFinish来判断是否完成任务。
第15行提供了一个完成任务时的事件,可以给客户程序注册。_index里存放了当前下载URL的个数。
该事件的定义是
1 2 3 4 5 6 | public delegate void DownloadFinishHandler(int count); /// <summary> /// 全部链接下载分析完毕后触发 /// </summary> public event DownloadFinishHandler DownloadFinish = null; |
3. 保存页面文件
这一部分可简单可复杂,如果只要简单地把HTML代码全部保存下来的话,直接存文件就行了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | private void SaveContents(string html, string url) { if (string.IsNullOrEmpty(html)) //判断html字符串是否有效 { return; } string path = string.Format("{0}\\{1}.txt", _path, _index++); //生成文件名 try { using (StreamWriter fs = new StreamWriter(path)) { fs.Write(html); //写文件 } } catch (IOException ioe) { MessageBox.Show("SaveContents IO" + ioe.Message + " path=" + path); } if (ContentsSaved != null) { _ui.Dispatcher.Invoke(ContentsSaved, path, url); //调用保存文件事件 } } |
第23行这里又出现了一个事件,是保存文件之后触发的,客户程序可以之前进行注册。
1 2 3 4 5 6 | public delegate void ContentsSavedHandler(string path, string url); /// <summary> /// 文件被保存到本地后触发 /// </summary> public event ContentsSavedHandler ContentsSaved = null; |
4. 提取页面链接
提取链接用正则表达式就能搞定了,不懂的可以上网搜。
下面的字符串就能匹配到页面中的链接
http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
1 2 3 4 5 6 7 8 9 10 11 12 13 | private string[] GetLinks(string html) { const string pattern = @"http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?"; Regex r = new Regex(pattern, RegexOptions.IgnoreCase); //新建正则模式 MatchCollection m = r.Matches(html); //获得匹配结果 string[] links = new string[m.Count]; for (int i = 0; i < m.Count; i++) { links[i] = m[i].ToString(); //提取出结果 } return links; } |
5. 链接的过滤
不是所有的链接我们都需要下载,所以通过过滤,去掉我们不需要的链接
这些链接一般有:
已经下载的链接
深度过大的链接
其他的不需要的资源,如图片、CSS等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | //判断链接是否已经下载或者已经处于未下载集合中 private bool UrlExists(string url) { bool result = _urlsUnload.ContainsKey(url); result |= _urlsLoaded.ContainsKey(url); return result; } private bool UrlAvailable(string url) { if (UrlExists(url)) { return false; //已经存在 } if (url.Contains(".jpg") || url.Contains(".gif") || url.Contains(".png") || url.Contains(".css") || url.Contains(".js")) { return false; //去掉一些图片之类的资源 } return true; } private void AddUrls(string[] urls, int depth) { if (depth >= _maxDepth) { return; //深度过大 } foreach (string url in urls) { string cleanUrl = url.Trim(); //去掉前后空格 cleanUrl = cleanUrl.TrimEnd('/'); //统一去掉最后面的'/' if (UrlAvailable(cleanUrl)) { if (cleanUrl.Contains(_baseUrl)) { _urlsUnload.Add(cleanUrl, depth); //是内链,直接加入未下载集合 } else { // 外链处理 } } } } |
第34行的_baseUrl是爬取的基地址,如http://news.sina.com.cn/,将会保存为news.sina.com.cn,当一个URL包含此字符串时,说明是该基地址下的链接;否则为外链。
_baseUrl的处理如下,_rootUrl是第一个要下载的URL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | /// <summary> /// 下载根Url /// </summary> public string RootUrl { get { return _rootUrl; } set { if (!value.Contains("http://")) { _rootUrl = "http://" + value; } else { _rootUrl = value; } _baseUrl = _rootUrl.Replace("www.", ""); //全站的话去掉www _baseUrl = _baseUrl.Replace("http://", ""); //去掉协议名 _baseUrl = _baseUrl.TrimEnd('/'); //去掉末尾的'/' } } |
至此,基本的爬虫功能实现就介绍完了。
发表评论或回复